
{kind=link}
To plot statistical graphics in Python, visualization libraries can be utilized, such because the “seaborn” library. By utilizing this library, customers can get the default kinds and colours to make plots extra comprehensible and enticing. It is usually built-in from “pandas” into the information construction and primarily based on the “matplotlib”.
This information will reveal about:
What’s a Cluster Map?
When customers plot a number of knowledge factors too shut to one another to find out the variation and draw a conclusion from the offered knowledge, it turns into troublesome. At the moment, the interactive map is called a “cluster map” through the use of the “sb.clustermap” It makes and represents a hierarchical cluster of the tuples and fields of the information.
What’s the “sb.clustermap()” Perform in Python?
The “sb.clustermap()” operate is used to plot statistical visuals and is predicated on the matplotlib software program that’s related with “pandas” knowledge constructions. The clustering strategies assist with the acquisition of structured knowledge in unsupervised studying.
Syntax
The final syntax of the “sb.clustermap()” operate is acknowledged under:
sb.clustermap(knowledge, standard_scale=None, figsize=(4, 7), **kwargs
Within the above-stated code block:
-
- “knowledge” parameter is the oblong knowledge that’s used for clustering. NULL values usually are not allowed.
- “standard_scale” parameter is used for substructuring the minimal and dividing every tuple or area by its most.
- “figsize” parameter is used for adjusting the general dimension of the determine that incorporates top and width.
How you can Plot Cluster Map Utilizing the “sb.clustermap()” Perform in Python?
To plot a cluster map utilizing the “sb.clustermap()” operate, first, import the required libraries as “seaborn”, and “matplotlib.pyplot”. Then, load the specified knowledge set through the use of the “load()” methodology with the “dropna()” methodology and go it to the “ds” variable. We now have used the “seaborn” library built-in dataset often known as “flights”. After that, name the “print()” methodology for getting the variety of rows and columns after which print the dataset.
import seaborn as sb
import matplotlib.pyplot as plt
ds = sns.load_dataset(‘flights’).dropna()
print(ds.form)
print(ds)
It may be noticed that the offered dataset is loaded efficiently:
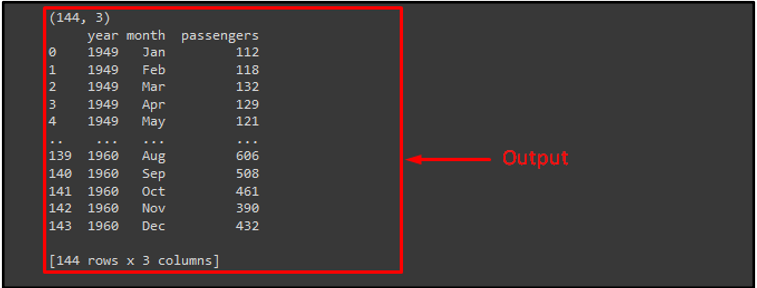
Now, use the “pop()” and go a dataset column identify that incorporates textual content values to pop whereas clustering the map. Then, name the “sb.clustermap()” together with the dataset, determine top and width, and cluster map coloration. Lastly, use the “plt.present()” methodology to show the plotted determine:
knowledge=ds.pop(‘month’)
sb.clustermap(ds, figsize=(6, 4), cmap=‘coolwarm’)
plt.present()
The offered determine is the output of the cluster map. It may be observed that the dataset rows and columns are rearranged by the Seaborn:
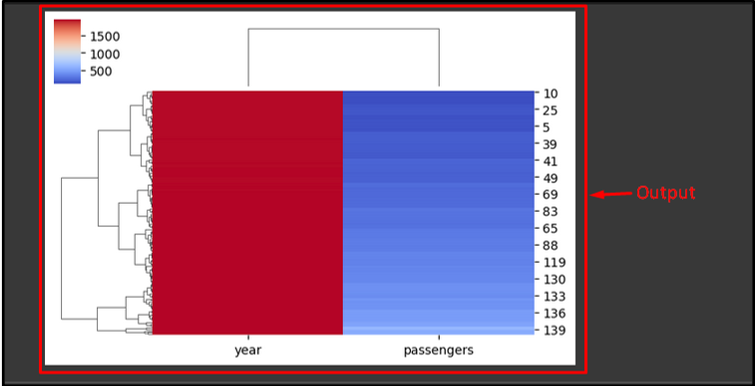
You could have discovered the tactic for making a cluster map in Python.
Conclusion
The “sb.clustermap()” operate is used for plotting statistical visuals that are primarily based on the matplotlib software program that’s related with “pandas” knowledge constructions. The clustering strategies assist with the acquisition of structured knowledge in unsupervised studying. This put up elaborated on the Seaborn cluster map in Python.