
{kind=link}
In Python 3, the urllib package deal permits customers to discover web sites from inside their script. The urllib incorporates a number of modules for managing completely different URL capabilities. When opening a URL in Python programming, the urllib library is essential. It permits you to go to and work together with web sites by using their Common Useful resource Locator. This library supplies us with packages like: urllib.request, urllib.error, urllib.parse, and urllib.robotparser.
On this snippet, regardless of this being a big subject to understand , we are going to merely take note of the urllib.parse module. Most notably, the urlparse() methodology.
The urllib.parse module is utilized for parsing the URLs of the web sites. It implies that by dividing a URL, we might get hold of its numerous elements. Moreover, it could be used to get any URL from a supply URL and reference path.
Loading the urllib:
Python contains urllib as a typical library. To make use of it, we should first import this library. For this, we are going to open the Spyder instrument and write the next command:
Urlparse() Module:
The urlparse() module gives an outlined methodology for parsing a uniform useful resource locator (URL) into distinct sections. To place it merely, this module permits us to simply separate URLs into completely different parts and filter out any explicit half from URLs. It simply merely cut up the URL into 6 parts which relate to the general syntax of a
URL: scheme:/netloc/path;parameters?question#fragment.
Let’s now start our tutorial with a sensible instance.
from urllib.parse import urlparse, urlunparse
On this code snippet, the very first thing we did is importing the urlparse and urlunparse from the urllib.parse. It will allow all of the required options of the urlparse() methodology in our instrument.
from urllib.parse import urlparse
exampleurl = urlparse(‘https://linuxhint.com/’)
print(“Url Parts:”,exampleurl)
Now, as we are able to use the urlparse() methodology. We now have outlined a variable named “exampleurl” which is able to retailer the string values. Then, we used the task operator “=” to assign values. Subsequent to it, we have now referred to as the “urlparse()” methodology. Contained in the braces of the urlparse() methodology, between the inverted commas, we have now outlined a URL of a selected web site on which we need to carry out the parsing. The braces of the print() assertion include a quoted textual content and the variable identify, separated by a comma.
The picture under exhibits us the next output.

You may see that the supplied URL is split into 6 parts. Now, earlier than we dip into studying these parts, we are going to first discover ways to put these parts again to the unique URL.
For this function, the strategy getting used is “urlunparse()”.
from urllib.parse import urlparse, urlunparse
exampleurl = urlparse(‘https://linuxhint.com/’)
print(“Url Parts:”,exampleurl)
unpar_url = urlunparse(exampleurl)
print(“Unique URL:” ,unpar_url)
We now have already imported the urlunparse from the urllib.parse within the above snippet. Now, we are going to create a variable named “unpar_url”. Invoking the “urlunparse()” methodology and writing the identify of the variable, we allocate the URL opening for the urlparse() methodology i.e. “exampleurl”. Within the final step, use the “print()” assertion to show a textual content and the variable identify for unparsing the URL.
The parsed URL is displayed within the picture connected under.
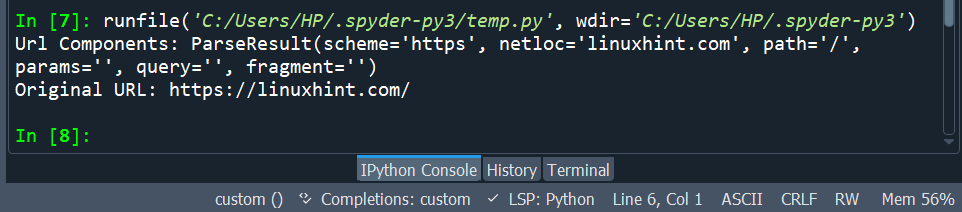
The utilization of the urlparse() and urlunparse() capabilities has been demonstrated. Now, allow us to discover the importance of each ingredient of the ParseResult that was returned.
Urlparse() Parts:
The urlparse() methodology splits the supplied URL into 6 chunks that are scheme, netloc, path, params, question, and fragment.
The primary part is the scheme. The scheme is utilized to specify the protocol that’s for use to amass the net assets which may very well be HTTP or HTTPS. The following part is netloc: web refers to community whereas loc means location. So, it tells us concerning the supplied URLs community location. The part path incorporates the exact pathway that an internet browser has to take to amass the supplied useful resource. The params are the trail parts’ parameters. The question adheres to the trail part and gives a stream of information that the useful resource can make the most of. The final part fragment merely classifies a component.
As beforehand talked about, every of those parts incorporates some knowledge on the URL. For the reason that returned object is supplied as a tuple, all these parts might also be retrieved using the index place.
from urllib.parse import urlparse
exampleurl = urlparse(‘https://linuxhint.com/’)
print(exampleurl.scheme, “==”,exampleurl[0])
print(exampleurl.netloc, “==”,exampleurl[1])
print(exampleurl.path, “==”,exampleurl[2])
print(exampleurl.params, “==”,exampleurl[3])
print(exampleurl.question, “==”,exampleurl[4])
print(exampleurl.fragment, “==”,exampleurl[5])
On this code snippet, we outlined indexes for every part individually contained in the print() assertion. We used the identify of the variable with the part identify in opposition to which we talked about the variable identify with the index place at which it lies within the stream. We are going to proceed to make use of this sequence till we have now talked about all of the parts with corresponding index positions.
Resultant strings will be seen within the picture right here.
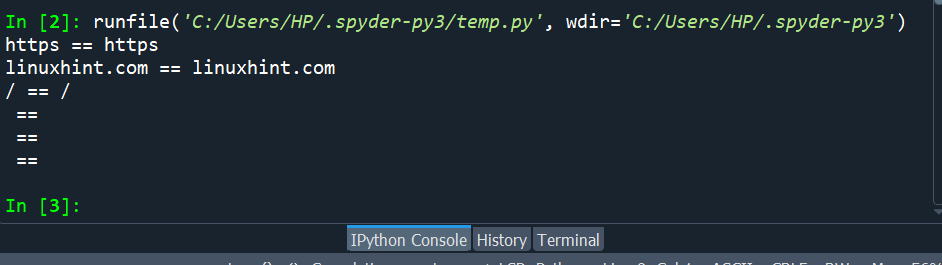
Though these make up the vast majority of the listed content material, extra key phrases may also be used to retrieve sure further functionalities resembling hostname, username, password, and port. The hostname identifies the hostname of the required URL, the username holds the identify of the consumer, the password retains the password consumer has supplied, whereas the port tells the port quantity.g
Conclusion
In at the moment’s subject, we have now mentioned the urlparse() module supplied by the urllib.parse. We defined the aim and usefulness of the urlparse() methodology. We elaborated on completely different parts of the urlparse() methodology and likewise how we make entry. By implementing the sensible instance codes on the URL of any specified web site using the Spyder instrument, we tried to make it easy, comprehensible but useful studying for you.