
{kind=link}
The content material of this information is given under:
Let’s begin with the primary methodology instantly!
Methodology 1: Utilizing Listing to Set Conversion
An inventory in Python can comprise duplicates, that means that there isn’t a uniqueness just like the one present in Python units. Subsequently, a straightforward option to detect if there are any duplicates inside a python listing is to transform it right into a set and evaluate the scale of each.
To reveal this, begin by creating a listing in Python through the use of the next code:
listVar = [123,46,11,78,334,46,98,11,90]
After that, use the set() methodology to transform this listing right into a set and retailer it inside a separate variable:
Print the variety of parts of each through the use of the len() methodology:
print(“Components in Listing: “,len(listVar))
print(“Components in Set: “,len(setVar))
When this code is executed, it produces the next outcomes on the terminal:
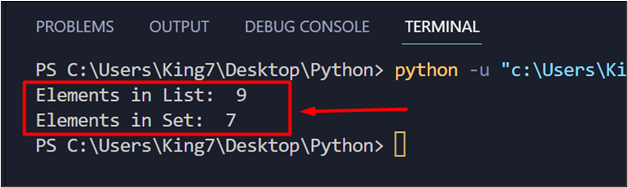
Based on the output, the variety of parts within the listing is 9 and 7 for the set. Because of this there are a complete of two duplicates within the Listing. However, as a substitute of manually calculating duplicates, you can even use the next line:
print(“Variety of Duplicates in Listing “,len(listVar)–len(setVar))
The whole code snippet with this new print assertion is:
listVar = [123,46,11,78,334,46,98,11,90]
setVar = set(listVar)
print(“Variety of Duplicates in Listing “,len(listVar)–len(setVar))
When this code is executed, it produces the next outcome on the terminal:
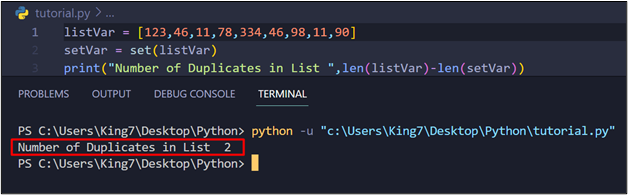
As you’ll be able to see from the output picture, there are a complete of two duplicates within the listing.
Methodology 2: Utilizing the Listing Comprehension and depend() Methodology
One other methodology of printing out the duplicates of a listing is through the use of the listing comprehension methodology to fetch every worth from the listing after which utilizing the depend() methodology to test its depend inside the listing. If the results of the depend() methodology is larger than one, then you’ll be able to add that aspect to a listing of duplicates.
To reveal the working of this methodology, take the next code:
duplicateVar =[]
for x in listVar:
if listVar.depend(x) > 1:
duplicateVar.append(x)
print(“The duplicates discovered within the listing are: “, duplicateVar)
When this code is executed, it produces the next outcome in your terminal:

As you’ll be able to see from the output, the values “46” and “11” have been current two occasions every.
Methodology 3: Utilizing the Listing Comprehension With If-not-in Situation
One other methodology of discovering duplicates in a listing is through the use of the listing comprehension and making use of the if-not-in situation.
Take the next code snippet for this methodology:
uniqueListVar = []
duplicateListVar = []
for x in listVar:
if x not in uniqueListVar:
uniqueListVar.append(x)
else:
duplicateListVar.append(x)
print(“The Listing of Distinctive Components is: “, uniqueListVar)
print(“The duplicates discovered within the listing are: “, duplicateListVar)
On this code snippet:
- Two new lists are created, one to retailer every distinctive worth, and one to retailer every repeating/duplicate worth
- Every aspect is checked in opposition to the values saved contained in the distinctive worth listing, and if it doesn’t exist already there, then it’s appended to it.
- If it already exists there, then it’s appended to the listing of duplicate values.
- On the finish, print each lists on the terminal utilizing the print() methodology
When this code is executed, it produces the next outcome in your terminal:
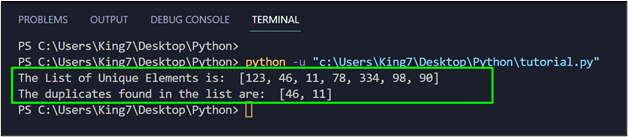
From the output, it may be seen that the values “46” and “11” have been duplicates and subsequently, solely certainly one of their cases is left within the listing of distinctive values.
Conclusion
To seek out duplicates in a listing, the person can make the most of completely different approaches that embrace changing the listing right into a string, utilizing the listing comprehension with the depend() methodology, or utilizing the if-not-in situation with the listing comprehension. Nonetheless, the quickest methodology to take away the duplicates from the listing is the conversion of the listing right into a set.