
{kind=link}
The best way to Discover First Prevalence in String?
To seek out the primary prevalence in a string, the next approaches can be utilized in Python:
Methodology 1: Discover First Prevalence in String Utilizing the “discover()” Methodology
The “discover()” methodology is utilized to seek out/get the primary prevalence of a specified/specific substring in an enter string. It retrieves the “index” of the primary look of the substring whether it is current within the specific string, in any other case, it retrieves “-1”.
Syntax
str.discover(sub[, start[, end]])
Within the above syntax:
- The “str” worth specifies the string during which the substring ought to be discovered.
- The “sub” parameter is the portion of the string we need to discover within the string.
- The “begin” (non-obligatory) parameter is the beginning index inside the string the place we need to begin looking for the substring.
- The “finish” (non-obligatory) parameter is the ending index inside the string the place we need to cease looking for the substring.
Instance
Let’s use the beneath instance code to seek out the primary prevalence within the string:
string = “Python Language, Java Language”
print(string.discover(“Language”));
Within the above code, the related “discover()” methodology is used to seek out the primary prevalence by taking the desired substring from the string as an argument.
Output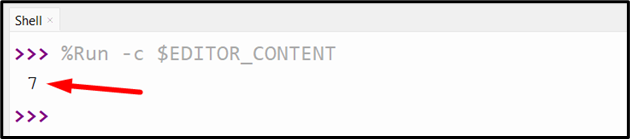
The above output snippet reveals that the desired string’s first prevalence is positioned at index “7”.
Methodology 2: Discover the First Prevalence within the String Utilizing the “index()” Methodology
The “index()” methodology is used to seek out/get the index worth of an merchandise/ingredient in a characters string or gadgets listing. This methodology retrieves the index worth of the primary prevalence of a component (in a listing) from the left facet of the listing. If the ingredient/merchandise doesn’t exist, it throws a “ValueError” exception.
Syntax
listing.index(ingredient, begin, finish)
On this syntax:
- The “ingredient” parameter specifies the ingredient that’s going to be searched within the listing.
- The “begin” and “finish” parameters are usually not obligatory and point out/specify the place to start out and finish the search.
Instance
The next instance code is used to seek out the primary occurrences within the string:
string = “Java Language, Python Language”
print(string.index(“Language”))
Within the above code block, the “string.index()” methodology takes the desired substring as a parameter and returns the index place of the primary prevalence of that specified substring within the given string.
Output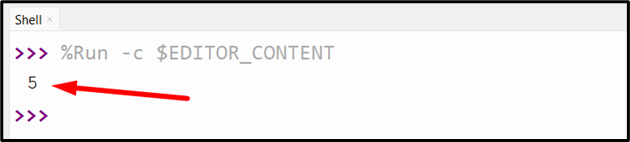
This end result reveals the primary occurrences i.e., “index” of a specified string within the enter string.
Methodology 3: Discover First Prevalence in String Utilizing the “rfind()” and “rindex()” Capabilities
The “rfind()” and “rindex()” features in Python are used to seek out the primary prevalence of a specified string within the given string, ranging from the appropriate facet of the string as an alternative of the left. The “rfind()” perform retrieves the index of the “1st” prevalence of the actual string, and the “rindex()” perform raises an exception if the desired string doesn’t exist/discovered.
Syntax
The syntax of “rfind()” perform in Python is as follows:
string.rfind(worth, begin, finish)
The syntax of the “rindex()” perform in Python is as follows:
string.rindex(worth, begin, finish)
Within the above given syntax of “rfind()” and “rindex()”:
- The “worth” parameter refers back to the worth to seek for within the given string.
- The “begin” is an non-obligatory parameter and it specifies the worth from the place to start out the search. (Default worth=“0”).
- The “finish” is a not obligatory parameter and it signifies the place the place to finish/shut the search. (Default= “string finish”).
Instance
Within the beneath code, the “rfind()” and “rindex()” features are used to seek out the primary prevalence within the string:
string = “Java Language, Python Language”
print(string.rfind(“Language”))
print(string.rindex(“Language”))
Within the above strains of code, the “rfind()” perform returns the best index of the substring “Language” from the principle string ranging from the appropriate facet of the string. Equally, the “rindex()” perform does precisely the identical factor as “rfind()”, nevertheless it raises an exception if it can not discover the substring.
Output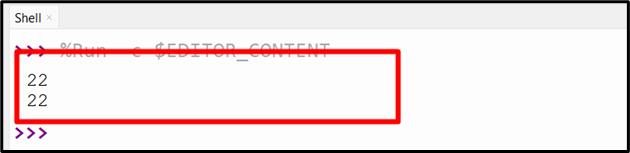
The above output shows the primary occurrences of the desired string in a string.
Conclusion
To seek out the primary prevalence in a string utilizing Python, the “discover()” methodology, the “index()” methodology, or the “rfind()” and “rindex()” features are used. The “discover()” and “index()” strategies return the index place of the primary cases of the actual/specified string in a given string. The “rfind()” and “rindex()” features discover the primary prevalence of a specified string within the given string, ranging from the appropriate facet of the string as an alternative of the left. This put up provided a number of methods to seek out/get the primary prevalence in a string using applicable examples.