
{kind=link}
As Linux customers, we work together with varied sorts of recordsdata regularly. One of the vital frequent file varieties on any pc system is a plain textual content file. Oftentimes, it’s a quite common requirement to seek out the required textual content in these recordsdata.
Nonetheless, this easy process rapidly turns into annoying if the file comprises duplicate entries. In such circumstances, we are able to use the uniq command to filter duplicate textual content effectively.
In Linux, we are able to use the uniq command that is useful once we wish to record or take away duplicate strains that current adjacently.
Other than this, we are able to additionally use the uniq command to depend duplicate entries. It is very important notice that, the uniq command works solely when duplicate entries are adjoining.
On this easy information, we are going to talk about the uniq command in-depth with sensible examples in Linux.
uniq Command Syntax
The syntax of the uniq command may be very simple to grasp and is much like different Linux instructions:
$ uniq [OPTIONS] [INPUT] [OUTPUT]
It is very important notice that, all of the choices and parameters of the uniq command are elective.
Creating Pattern Textual content File
To start, first, let’s create a easy textual content file with a vi editor and add the next duplicate contents situated within the adjoining strains.
$ vi linux-distributions.txt $ cat linux-distributions.txt
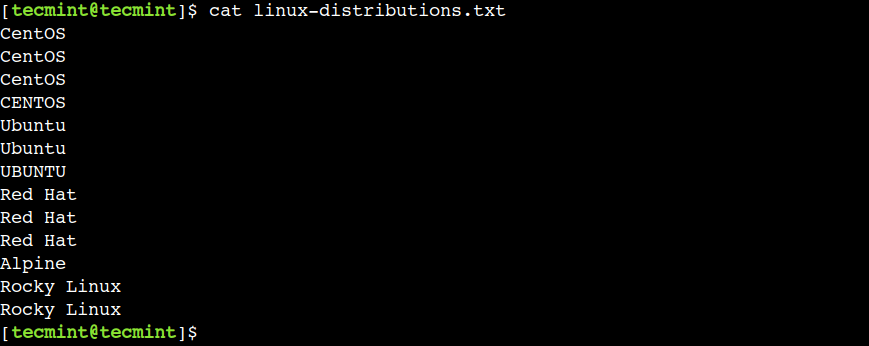
Now, let’s use this file to grasp the utilization of the uniq command.
1. Take away Duplicate Traces from a Textual content File
One of many frequent makes use of of the uniq command is to take away the adjoining duplicate strains from the textual content file as proven.
$ uniq linux-distributions.txt
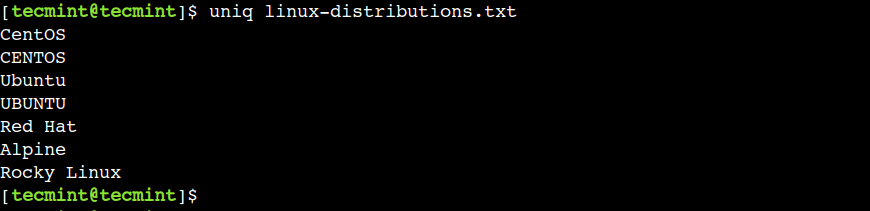
Within the above output, we are able to see that the uniq command has efficiently eradicated the duplicated strains.
2. Rely Duplicated Traces in a Textual content File
Within the earlier instance, we noticed the right way to take away duplicate strains. Nonetheless, typically we additionally wish to know what number of instances the duplicate line seems.
We are able to obtain this utilizing the -c possibility as proven within the under instance:
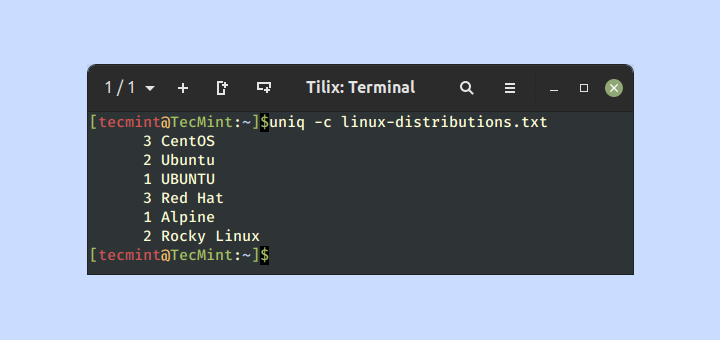
$ uniq -c linux-distributions.txt
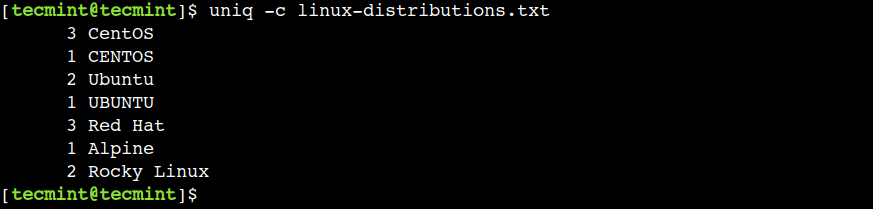
Within the above output, the primary column represents the variety of instances the road is repeated.
3. Take away Duplicates with Case Insensitive
By default, the uniq command works in a case-sensitive method. Nonetheless, we are able to disable this default conduct through the use of the -i possibility as proven.
$ uniq -i linux-distributions.txt

On this instance, we are able to observe that now, the string Ubuntu and UBUNTU is handled as identical. Together with this, the identical occurs with the string CentOS and CENTOS.
4. Print Solely Duplicate Traces from a File
Generally, we would like simply wish to print the duplicate strains from a textual content file, in that case, you should use the -d possibility as proven.
$ uniq -d linux-distributions.txt

Within the above output, we are able to see that the uniq command exhibits the duplicate entry from every group.
5. Print All Duplicate Traces from a File
Within the earlier instance, we noticed the right way to show a replica line from every group. In the same method, we are able to additionally present all of the duplicates strains utilizing the -D possibility:
$ uniq -D linux-distributions.txt
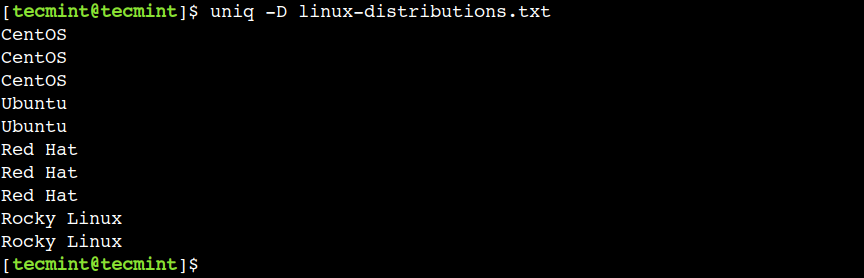
The above output doesn’t present the textual content UBUNTU, CENTOS, and Alpine as these are uniq strains.
6. Present Duplicate Traces By Teams in a New Line
Within the earlier instance, we printed all duplicate strains. Nonetheless, we are able to make the identical output extra readable by separating every group by a brand new line.
Let’s use the --all-repeated=separate possibility to attain the identical:
$ uniq --all-repeated=separate linux-distributions.txt
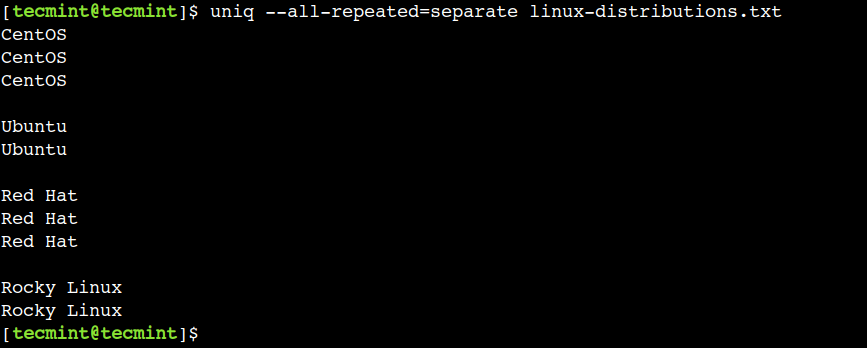
Within the above output, we are able to see that every repeated group is separated by a brand new line delimiter.
7. Print Solely Distinctive Traces from a File
In earlier examples, we noticed the right way to print duplicate strains. Equally, we are able to additionally instruct the uniq command to print non-duplicate strains solely.
Now, let’s use the -u choice to print distinctive strains solely:
$ uniq -u linux-distributions.txt

Right here, we are able to see that the uniq command shows the strains that aren’t duplicated.
8. Take away Non-adjacent Duplicate Traces in File
One of many trivial limitations of the uniq command is that it solely removes adjoining duplicate entries. Nonetheless, typically we wish to take away the duplicate entries no matter their order within the given file.
In such circumstances, first, we are able to kind the file contents after which pipe that output to the uniq command as proven.
$ kind linux-distributions.txt | uniq
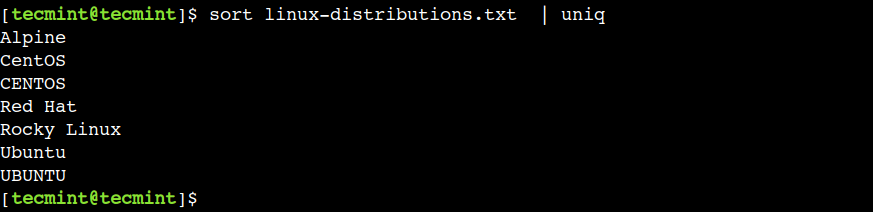
On this instance, we used the kind and uniq instructions with none choices. Nonetheless, we are able to additionally mix different supported choices with these instructions.
Conclusion
On this information, we discovered the uniq command utilizing sensible examples. Have you learnt of some other finest instance of the uniq command in Linux? Tell us your views within the feedback under.
If You Recognize What We Do Right here On TecMint, You Ought to Contemplate:
TecMint is the quickest rising and most trusted group website for any type of Linux Articles, Guides and Books on the internet. Tens of millions of individuals go to TecMint! to go looking or browse the 1000’s of revealed articles out there FREELY to all.
Should you like what you’re studying, please take into account shopping for us a espresso ( or 2 ) as a token of appreciation.

We’re grateful in your by no means ending help.