
{kind=link}
Syntax:
DataFrame_object.apply(func, axis=0, uncooked=False, result_type=None, args=(), **kwargs)
Parameters:
- Func: A customized/in-built perform that may be utilized on the rows/columns.
- axis: {columns (1), index (0)}
- skipna: Ignore the NA/null values when calculating the consequence.
- result_type: Returned kind of the consequence like Collection,DataFrame, and many others.
- args: Specify the arguments.
Methodology 1: Apply() with Customized Operate
To do some operation on all of the rows within the Pandas DataFrame, we have to write a perform that may do the computation and cross the perform identify throughout the apply() methodology. By this, the perform is utilized to each row.
pandas.DataFrame_object.apply(custom_function)
Instance:
On this instance, we’re having a DataFrame named “evaluation” with 4 columns of integer kind. Now, we write two customized features on these 4 columns.
- The “operation1” provides rows in all of the columns. The consequence throughout every column is saved within the “Addition Outcome” column.
- The “operation2” multiplies the rows in all of the columns. The consequence throughout every column is saved within the “Multiplication Outcome” column.
# Create the dataframe utilizing lists
evaluation = pandas.DataFrame([[23,1000,34,56],
[23,700,11,0],
[23,20,4,2],
[21,400,32,45],
[21,100,456,78],
[23,800,90,12],
[21,400,32,45],
[20,120,1,67],
[23,100,90,12],
[22,450,76,56],
[22,40,0,1],
[22,12,45,0]
],columns=[‘points1’,‘points2’,‘points3’,‘points4’])
# Show the DataFrame – evaluation
print(evaluation)
# Operate that provides every row for all columns.
def operation1(row):
return row[0]+row[1]+row[2]+row[3]
# Operate that provides every row for all columns.
def operation2(row):
return row[0]*row[1]*row[2]*row[3]
# Cross the perform to the apply() methodology and retailer it in ‘Addition Outcome’ column
evaluation[‘Addition Result’] = evaluation.apply(operation1, axis=1)
# Cross the perform to the apply() methodology and retailer it in ‘Multiplication Outcome’ column
evaluation[‘Multiplication Result’] = evaluation.apply(operation2, axis=1)
print()
print(evaluation)
Output: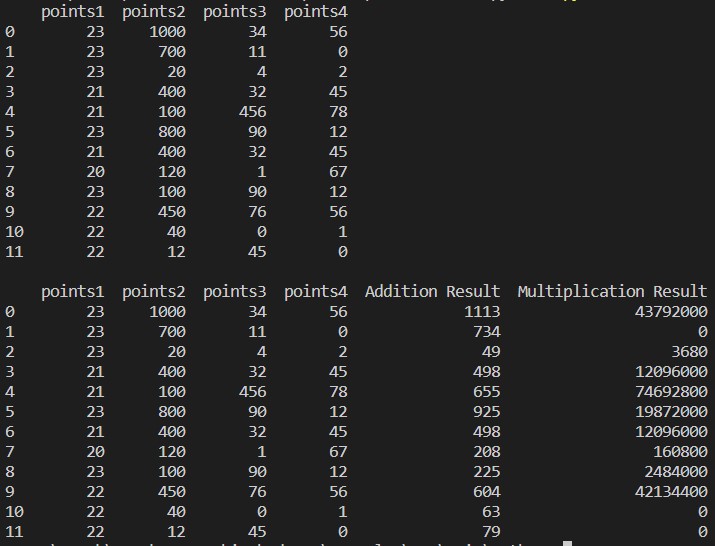
Rationalization:
We cross the “operation1” and “operation2” to the apply() perform individually one after the opposite. You may see that the sum of all values throughout every row is saved within the “Addition Outcome” column and the product of all values throughout every row is saved in “Multiplication Outcome” column.
Methodology 2: Apply() with Lambda Expression
Right here, we cross the lambda as a parameter to the apply() perform and do the computation inside itself.
pandas.DataFrame_object.apply(lambda x: computation,axis=1)
Instance:
Let’s add and multiply 4 rows just like the earlier instance and retailer them in two columns.
# Create the dataframe utilizing lists
evaluation = pandas.DataFrame([[23,1000,34,56],
[23,700,11,0],
[23,20,4,2],
[21,400,32,45],
[21,100,456,78],
[23,800,90,12],
[21,400,32,45],
[20,120,1,67],
[23,100,90,12],
[22,450,76,56],
[22,40,0,1],
[22,12,45,0]
],columns=[‘points1’,‘points2’,‘points3’,‘points4’])
# Add all rows and retailer them within the ‘Addition Outcome’ column.
evaluation[‘Addition Result’] = evaluation.apply(lambda report : report[0]+report[1]+report[2]+report[3], axis=1)
# Multiply all rows and retailer them within the ‘Multiplication Outcome’ column.
evaluation[‘Multiplication Result’] = evaluation.apply(lambda report : report[0]*report[1]*report[2]*report[3], axis=1)
print()
print(evaluation)
Output: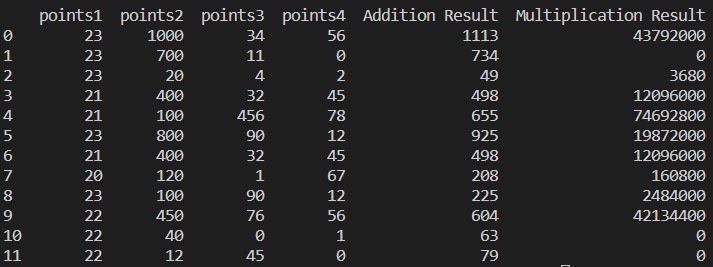
Rationalization:
The expressions which are used are as follows:
evaluation[‘Addition Result’] = evaluation.apply(lambda report : report[0]+report[1]+report[2]+report[3], axis=1)
# Multiply all rows and retailer them within the ‘Multiplication Outcome’ column.
evaluation[‘Multiplication Result’] = evaluation.apply(lambda report : report[0]*report[1]*report[2]*report[3], axis=1)
You may see that the sum of all values throughout every row is saved within the “Addition Outcome” column and the product of all values throughout every row is saved within the “Multiplication Outcome” column.
Methodology 3: Apply() with Pandas.Collection
If you wish to modify the row individually otherwise you wish to replace all rows individually, you are able to do it by passing the Collection contained in the lambda expression.
pandas.DataFrame_object.apply(lambda x: pandas.Collection(computation),axis=1)
Instance:
Let’s subtract 10 from all columns.
# Create the dataframe utilizing lists
evaluation = pandas.DataFrame([[23,1000,34,56],
[23,700,11,0],
[23,20,4,2],
[21,400,32,45],
[21,100,456,78],
[23,800,90,12],
[21,400,32,45],
[20,120,1,67],
[23,100,90,12],
[22,450,76,56],
[22,40,0,1],
[22,12,45,0]
],columns=[‘points1’,‘points2’,‘points3’,‘points4’])
# Subtract 10 from all of the rows
evaluation=evaluation.apply(lambda report : pandas.Collection([record[0]–10,report[1]–10,report[2]–10,report[3]–10]), axis=1)
print(evaluation)
Output: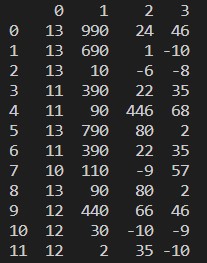
Rationalization:
The expressions which are used are as follows:
evaluation=evaluation.apply(lambda report : pandas.Collection([record[0]–10,report[1]–10,report[2]–10,report[3]–10]), axis=1)
You may see that the values in all columns are subtracted from 10.
Methodology 4: Apply() with NumPy Capabilities
Let’s use the NumPy features to carry out the computation on all rows in Pandas DataFrame.
pandas.DataFrame_object.apply(numpy perform,axis=1)
Instance:
Let’s use the NumPy perform to return the next:
- The sum of all rows utilizing numpy.sum().
- The typical of all rows utilizing numpy.imply().
- The utmost amongst every row utilizing numpy.max().
- The minimal amongst every row utilizing numpy.min().
We retailer the end in 4 totally different columns.
import numpy
# Create the dataframe utilizing lists
evaluation = pandas.DataFrame([[23,1000,34,56],
[23,700,11,0],
[23,20,4,2],
[21,400,32,45],
[21,100,456,78],
[23,800,90,12],
[21,400,32,45],
[20,120,1,67],
[23,100,90,12],
[22,450,76,56],
[22,40,0,1],
[22,12,45,0]
],columns=[‘points1’,‘points2’,‘points3’,‘points4’])
# Get whole sum of rows and retailer in ‘Sum Outcome’
evaluation[‘Sum Result’] = evaluation.apply(numpy.sum, axis = 1)
# Get common of rows and retailer in ‘Sum Outcome’
evaluation[‘Average Result’] = evaluation.apply(numpy.imply, axis = 1)
# Get most worth from every row and retailer in ‘Max Outcome’
evaluation[‘Max Result’] = evaluation.apply(numpy.max, axis = 1)
# Get minimal worth from every row and retailer in ‘Min Outcome’
evaluation[‘Min Result’] = evaluation.apply(numpy.min, axis = 1)
print(evaluation)
Output: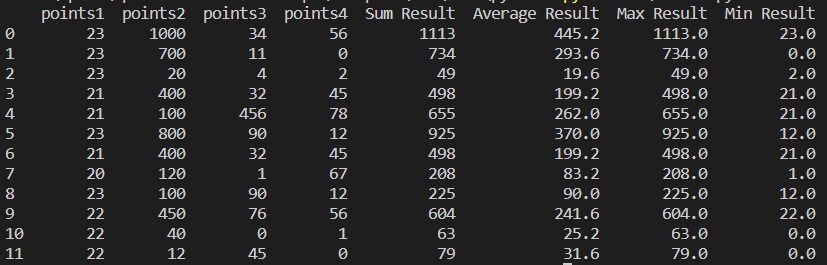
Conclusion
We offered this information to clarify learn how to make the most of the apply() perform to each row. Our primary goal is to offer you a superb, simple, and detailed clarification of this “apply()” perform idea. We demonstrated 4 distinct examples through which we confirmed learn how to apply the perform to each row in “pandas” with the assistance of the “apply()” perform. We defined that once we wish to implement any perform to each row in DataFrame in Pandas, we make the most of the “apply()” perform for this function.